
キャラクターエディット自体は形になっていて、キャラくったーのチャットの機能が一通り書き終わって、統合してのエラー出し中。キャラクターのチャットができれば、今の最新のllmならかなり自律的に動いてくれるのではないかと期待している。
レンチキュラーレンズというのを使えば裸眼立体視ができるというのを見て試してみたくてうずうずしている。それもキャラくてーチャットができてから。
キャラクターエディット自体は形になっていて、キャラくったーのチャットの機能が一通り書き終わって、統合してのエラー出し中。キャラクターのチャットができれば、今の最新のllmならかなり自律的に動いてくれるのではないかと期待している。
レンチキュラーレンズというのを使えば裸眼立体視ができるというのを見て試してみたくてうずうずしている。それもキャラくてーチャットができてから。
NemoClawを試してみようと思って
少し躓いたところのメモ
windows側のlmstudioにwslからアクセスしようとしたら、上手くいかなかったときのメモ
“powershell“で
notepad %UserProfile%\.wslconfig
または
code %UserProfile%\.wslconfig
以下を追加、保存
[wsl2]
networkingMode=mirrored
……
discodeにうまくつながってくれない。ので今保留中。
なんというかAIでコードの作成は早くなったけど、仕様の言語化がボトルネック。この辺りもAIで解決できるようになるのかな。
だいぶ形になってきたかな。保存と呼び出しはできたけど、いろいろ使いづらい。
ローカルAIで雑談をするモデルというのがあったので試してみたけど、その過程で思わぬことを発見。ローカルAIはしりとりがまともにできない。
一番まともにできたのが oss-gpt 20Bだった. ほかのモデルはルールをろくに知らなかったり、終わりの文字をでなく母音で判断したりして正常にゲームできなかった。
現在ファイル周りやっている。AICharacterが関数を読み込んだりできるようにしなくてはいけないので、なんだかコードがややこしい。
GUI周りの再現にも苦戦している。
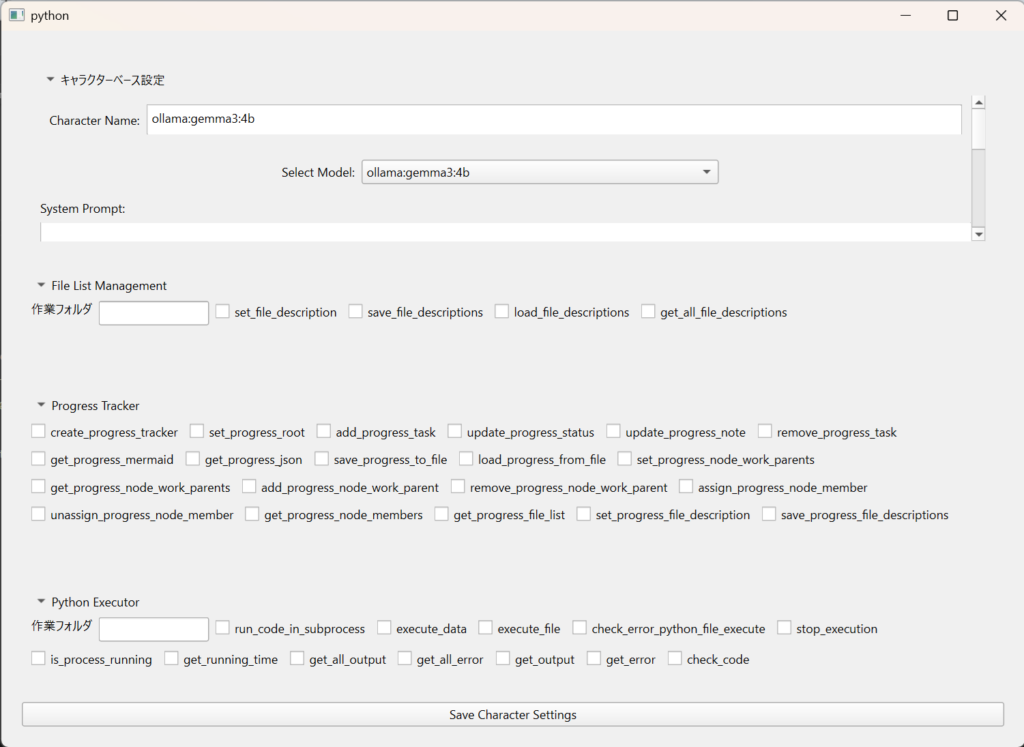
キャラクターエディタの現状。
下のほうのtyっくバックスは指定の書式で書いておくと自動登録されるようにしてある。見栄えを整えたいがそれは後回し。
以前作った記憶のあるコードが見つからないとなんかへこむよね。
LMstudioのバージョンアップが来てて、thinkingが取れなかったのopenai apiの問題を修正とかのってんだけど。
今確認してみたけど、自分の書いたコードに影響は与えなそうなのでよかった。
LMstudio周りの不具合修正完了。表記がopenaiとなっていたため、スレッド切り替え時聖女に読み込めない問題を修正。表記自体をlmstudioと表示されるように修正。thinkingもとれるようにした。
キャラクターエディットに取り掛かる。キャラクターエディットが出来上がったらまとめてアップロード予定。
LMstudioのモデルを使用すると不具合が出てたのだな。thinking をとれないのでOllamaで動作確認していいたから気が付かなかった。キャラクターエディット機能作っているからそれと共に修正を公開かな。
エージェントを作ることを考えると今のllmbaseはほとんど使いまわせないので、llmbaseからいくつかの関数をAICharacterに移動。
エージェント用と通常チャット用で作り分けしないといけないので、AICharacterを分けるかも。
そう追加もしてどうにか動くところまで行った。