
目的
平方根の活性化関数の項目でreluがtanhや平方根を180度対称にした関数よりも学習が進んでいた理由を探る。
条件
前回の結果から、今回はプラスしかとらない関数を考える。
まず、xが0より大きな領域は、reluと同じになるように傾き1の直線とした。
また、xがマイナスとなる時、reluのように0以下で傾きが0にならないようにし、学習が止まらないようにした。
そして、以下のようなxが0以下の時次のような3つの違いを出した。
1,緩やかに0に近づく(softplus_linear)
2,傾きを反転する(refractioin_linear)
3,無理やりプラスにする。(各層の最小値を引く)(zero_fit_linear)
これらを実現する方法として次のような手段を取った。
1は、tensorflowのsftplusを2倍にする関数を0以下で使用することにした。2倍したのは0の時の傾きを1にするため。
2は、0以下は-xの値を返すようにした。
3は各層の最小値を求めxから引くという事をした。
テスト用コードのベースは前回と同じ。
import tensorflow as tf
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.utils import to_categorical
import time
# CIFAR-10 データの読み込み
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# 正規化
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
# ラベルを one-hot エンコーディング
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
# モデルの構築
model = Sequential([
Conv2D(32, (3, 3), activation='relu', padding='same', input_shape=(32, 32, 3)),
Conv2D(32, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Dropout(0.25),
Conv2D(64, (3, 3), activation='relu', padding='same'),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Dropout(0.25),
Flatten(),
Dense(512, activation='relu'),
Dropout(0.5),
Dense(10, activation='softmax')
])
# モデルのコンパイル
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# モデルの訓練
history = model.fit(x_train, y_train, batch_size=64, epochs=50, validation_data=(x_test, y_test), verbose=2)
# モデルの評価
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
print("time", time.time() - start_t)
loss = history.history['loss']
accuracy = history.history['accuracy']
val_loss = history.history['val_loss']
val_accuracy = history.history['val_accuracy']
import pandas as pd
df = pd.DataFrame({'loss': loss, 'accuracy': accuracy, 'val_loss': val_loss, 'val_accuracy': val_accuracy})
df.to_csv('fime_name.csv', index=False)を使用し、’relu’ を置き替える。
1、softplu+linerの関数のコード
g_cx = tf.constant(0.0) # 例として0を入力とする
g_softplus_2 = 2 * tf.nn.softplus(g_cx)
def softplus_linear(x):
return tf.where(x <= 0, 2 * tf.nn.softplus(x), x + g_softplus_2)2、 0で傾きを反転するlinearのコード
def reflection_linear(x):
return tf.where(x <= 0, -x, x)3, 最小値を引き無理やりプラスにするライナーのコード
def zero_fit_linear_CNN(x):
min_vals = tf.math.reduce_min(x, axis=(1, 2), keepdims=True)
return x - min_vals
def zero_fit_linear_Dence(x):
min_vals = tf.math.reduce_min(x, axis=1, keepdims=True)
return x - min_valszero_fit_liner_CNNはCNN部分の’relu’を置き換え
zero_fit_liner_DenseはDense部分の’relu’を置き換え
結果の予想
1、softplu_linear:0以下の時も学習し続けるのでreluよりいい成績になる。過学習も起きづらい。
2,0で傾き反転:反転させるので学習が安定せず正答率があまり上がらない。
3,本来マイナスの部分でもしっかり学習されるので良い成績を出す可能性あり。ただし、ただのlinearとして学習があまり進まない可能性もある。
結果
前回のrelueの結果も併せて表にすると以下のようになった。zero_fit_linearのfunnctionのグラフは毎回位置が変わるので参考程度のもの。softplusのlossの最大値は他のlossのグラフの最大値より大きめにして特徴的な形が表示されるようにしている。「
| relu | softplus_linear | |
| function | 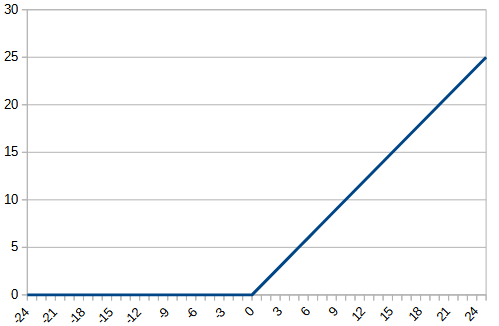 | 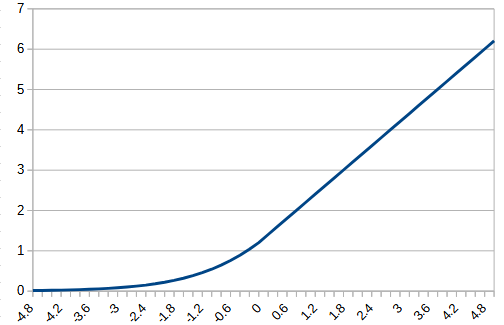 |
| accuracy | 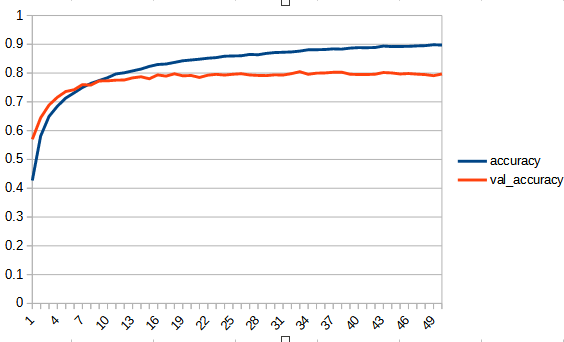 | 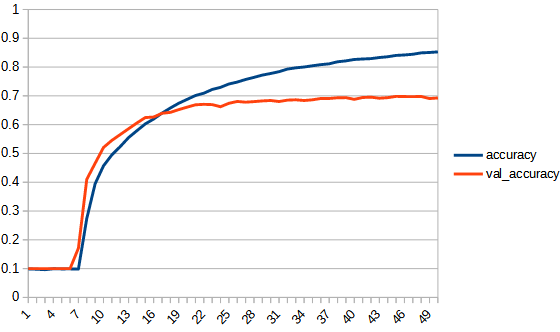 |
| loss | 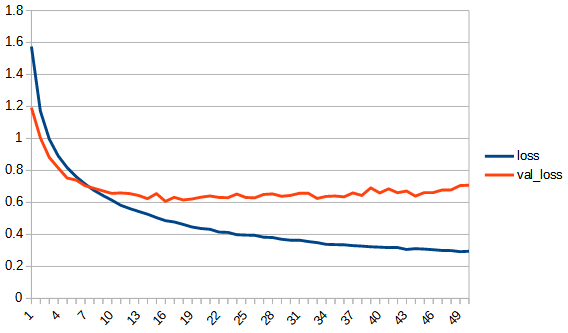 | 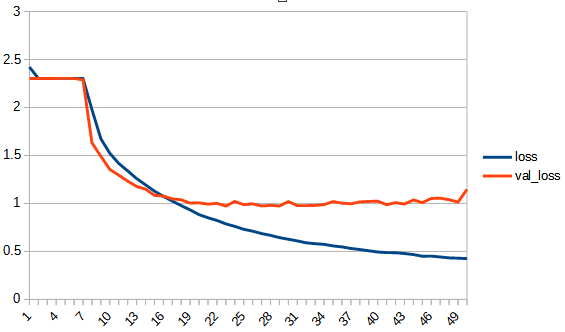 |
| csv | reluダウンロード | softplus_linearrダウンロード |
| refraction_linear | zero_fit_linear | |
| function | 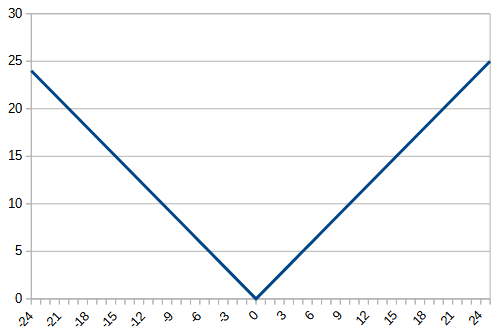 | 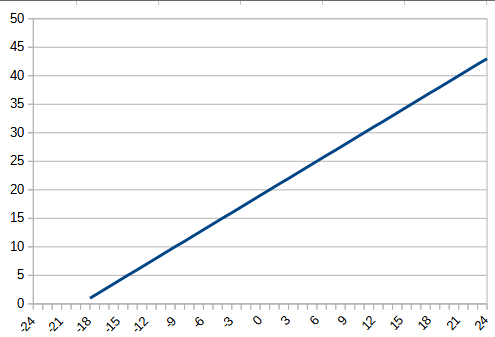 |
| accuracy | 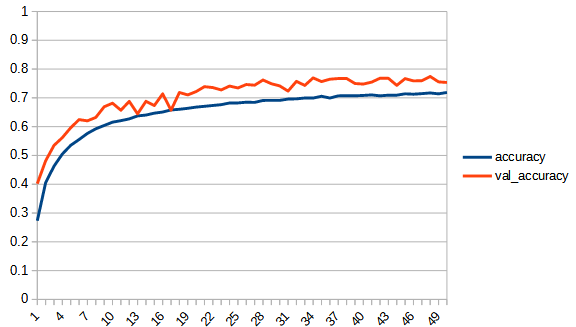 | 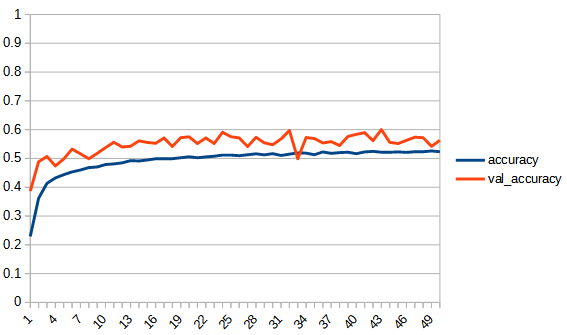 |
| loss | 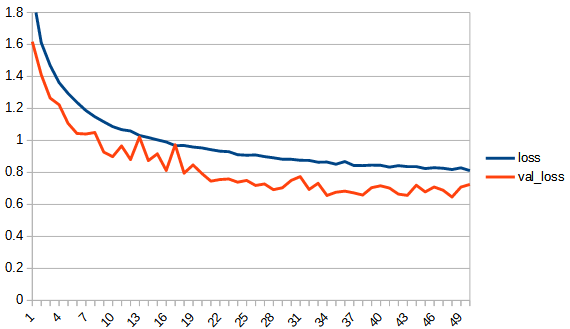 | 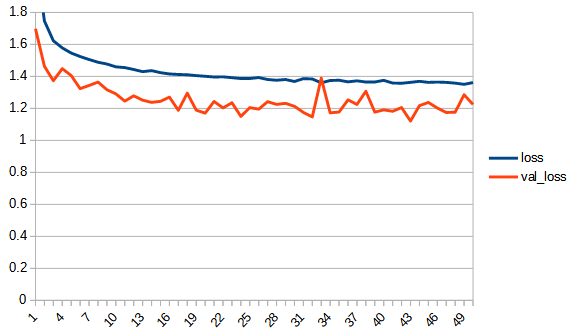 |
| csv | reflection_linearダウンロード | zero_fit_linerダウンロード |
1, softplus_linear
初めは学習が進まないが途中から進み過学習に陥っている。val_accuracyは0.7ぐらいで頭打ちとなっており、reluよりは低い。
2, refraction_linear
もっと不安定になるかと思ったが、意外とトレーニングデータの学習曲線はなめらかである。過学習の様子は見られない。val_accuracyは0.7ぐらいで頭打ちとなっており、reluよりは低い。
3, zero_fit_liner
過学習の兆候は見られないが、正答率は低い。linearとして学習が進まなかったと思われる。
recraction_linearが一番よさそうな結果であるがそれでもval_accuracyは0.7程度である。
softplus_linearは、初め全く学習が進まないという現象はよくわからないが、全体としてもreluと同じような過学習になってしまうのは少し意外だった。0以下も学習を続けられるようにしているのに効果が見られない。
zero_fit_linearは、最小値を引くという操作はおそらくあまり意味がないようだ。正答率は上がらなかった。
考察
常にプラスであるという事は、reluの正答率の良さあまり関係ない可能性が高い。reluの検証してない特徴は傾きが0になることである。正直この部分は、学習が止まってしまうという意味で、学習には悪影響であると思っていたが、もしかしたら違うかもしれない。次回はそこを調べる。